Transformers have gained significant attention due to their powerful capabilities in understanding and generating human-like text, making them suitable for various applications like language translation, summarization, and creative content generation. They operate based on an attention mechanism, which determines how much focus each token in a sequence should have on others to make informed predictions. While they offer great promise, the challenge lies in optimizing these models to handle large amounts of data efficiently without excessive computational costs.
A significant challenge in developing transformer models is their inefficiency when handling long text sequences. As the context length increases, the computational and memory requirements grow exponentially. This happens because each token interacts with every other token in the sequence, leading to quadratic complexity that quickly becomes unmanageable. This limitation constrains the application of transformers in tasks that demand long contexts, such as language modeling and document summarization, where retaining and processing the entire sequence is crucial for maintaining context and coherence. Thus, solutions are needed to reduce the computational burden while retaining the model’s effectiveness.
Approaches to address this issue have included sparse attention mechanisms, which limit the number of interactions between tokens, and context compression techniques that reduce the sequence length by summarizing past information. These methods attempt to reduce the number of tokens considered in the attention mechanism but often do so at the cost of performance, as reducing context can lead to a loss of critical information. This trade-off between efficiency and performance has prompted researchers to explore new methods to maintain high accuracy while reducing computational and memory requirements.
Researchers at Google Research have introduced a novel approach called Selective Attention, which aims to enhance the efficiency of transformer models by enabling the model to ignore no longer relevant tokens dynamically. The method allows each token in a sequence to decide whether other tokens are needed for future computations. The key innovation lies in adding a selection mechanism to the standard attention process, reducing the attention paid to irrelevant tokens. This mechanism does not introduce new parameters or require extensive computations, making it a lightweight and effective solution for optimizing transformers.
The Selective Attention technique is implemented using a soft-mask matrix that determines the importance of each token to future tokens. The values in this matrix are accumulated over all tokens and then subtracted from the attention scores before computing the weights. This modification ensures that unimportant tokens receive less attention, allowing the model to ignore them in subsequent computations. By doing so, transformers equipped with Selective Attention can operate with fewer resources while maintaining high performance across different contexts. Further, the context size can be pruned by removing unnecessary tokens, reducing memory and computational costs during inference.
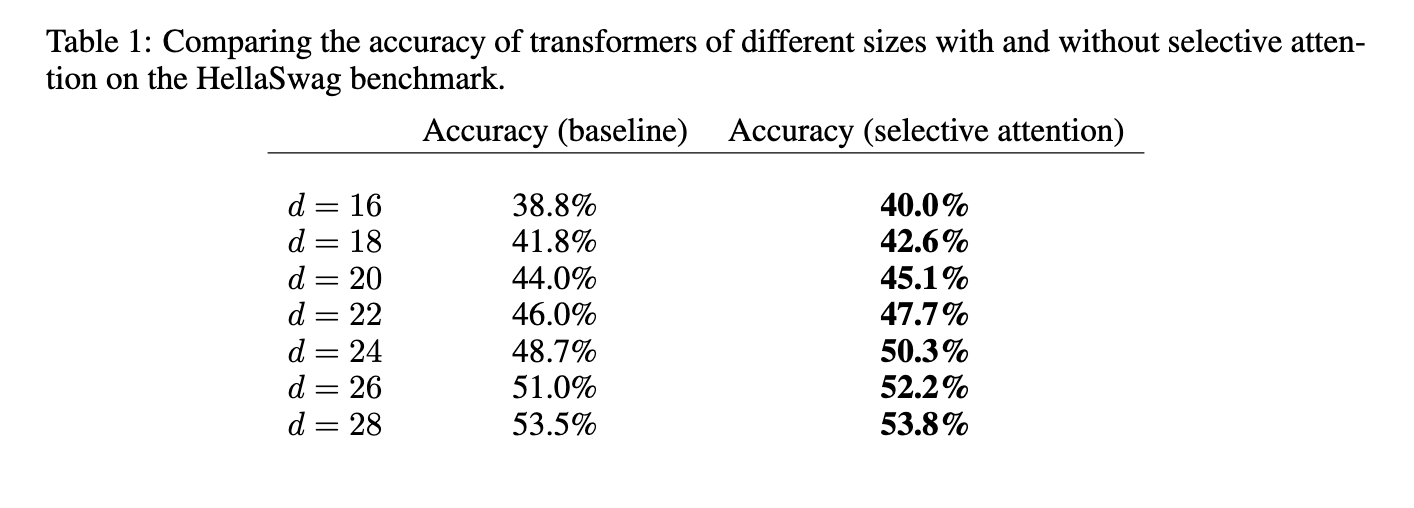
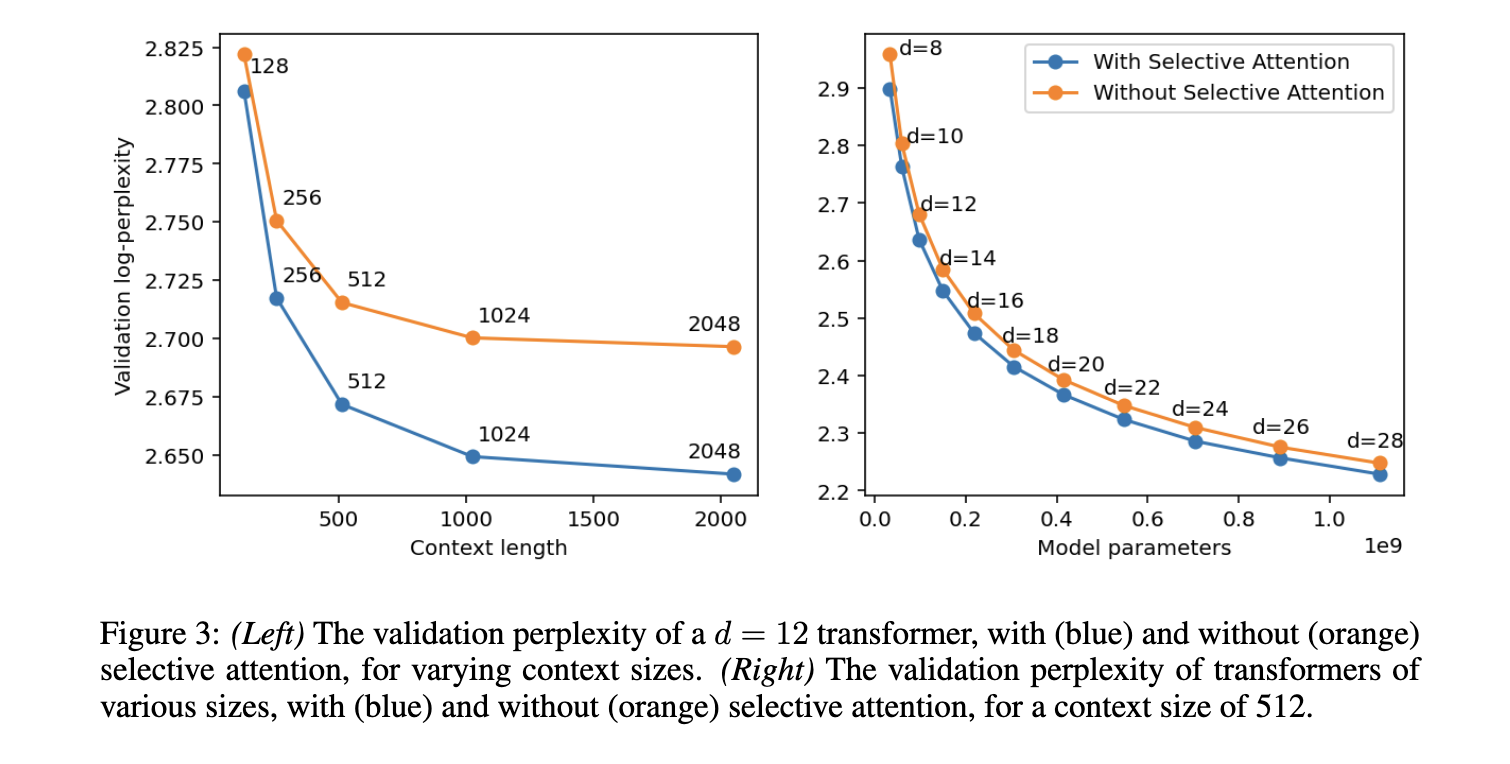
The researchers conducted extensive experiments to evaluate the performance of Selective Attention across various natural language processing tasks. The results showed that Selective Attention transformers achieved similar or better performance than standard transformers while significantly reducing memory usage and computational costs. For example, in a transformer model with 100 million parameters, the memory requirements for the attention module were reduced by factors of 16, 25, and 47 for context sizes of 512, 1,024, and 2,048 tokens, respectively. The proposed method also outperformed traditional transformers on the HellaSwag benchmark, achieving an accuracy improvement of up to 5% for larger model sizes. This substantial memory reduction directly translates into more efficient inference, making deploying these models in resource-constrained environments feasible.
Further analysis showed that transformers equipped with Selective Attention could match the performance of traditional transformers with twice as many attention heads and parameters. This finding is significant because the proposed method allows for smaller, more efficient models without compromising accuracy. For example, in the validation set of the C4 language modeling task, transformers with Selective Attention maintained comparable perplexity scores while requiring up to 47 times less memory in some configurations. This breakthrough paves the way for deploying high-performance language models in environments with limited computational resources, such as mobile devices or edge computing platforms.
In conclusion, Google Research’s development of Selective Attention addresses the key challenge of high memory and computational costs in transformer models. The technique introduces a simple yet powerful modification that enhances the efficiency of transformers without adding complexity. By enabling the model to focus on important tokens and ignore others, Selective Attention improves both performance and efficiency, making it a valuable advancement in natural language processing. The results achieved through this method have the potential to expand the applicability of transformers to a broader range of tasks and environments, contributing to the ongoing progress in artificial intelligence research and applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
Interested in promoting your company, product, service, or event to over 1 Million AI developers and researchers? Let’s collaborate!
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.





